Decision-Language Model (DLM)
for Dynamic Restless Multi-Armed Bandit Tasks in Public Health
Abstract
Restless multi-armed bandits (RMAB) have demonstrated success in optimizing resource allocation for large beneficiary populations in public health settings. Unfortunately, RMAB models lack flexibility to adapt to evolving public health policy priorities. Concurrently, Large Language Models (LLMs) have emerged as adept automated planners across domains of robotic control and navigation. In this paper, we propose a Decision Language Model (DLM) for RMABs, enabling dynamic fine-tuning of RMAB policies in public health settings using human-language commands. We propose using LLMs as automated planners to (1) interpret human policy preference prompts, (2) propose reward functions as code for a multi-agent RMAB environment, and (3) iterate on the generated reward functions using feedback from grounded RMAB simulations. We illustrate the application of DLM in collaboration with ARMMAN, an India-based non-profit promoting preventative care for pregnant mothers, that currently relies on RMAB policies to optimally allocate health worker calls to low-resource populations. We conduct a technology demonstration in simulation using the Gemini Pro model, showing DLM can dynamically shape policy outcomes using only human prompts as input.
Method

We provide three context descriptions to the LLM: a language command (full list of commands in Table 1), a list of per-arm demographic features available for proposed reward functions, and syntax cues enabling LLM reward function output directly in code. From this context, the 1) LLM then proposes 2) candidate reward functions which are used to train 3) optimal policies under proposed rewards. Trained policies are simulated to generate 4) policy outcome comparisons showing state-feature distributions over key demographic groups. Finally, we query an LLM to perform 5) self-reflection by choosing the best candidate reward aligning with the original language command; selected candidates are used as context to guide future reward generation.

In the reward function generation phase, the LLM is prompted with three key components: (1) a human-language command describing a desired policy outcome for a feature-based group, (2) feature information such as demographics or socioeconomic data relevant to policy outcomes, and (3) context regarding the RMAB setting and code implementation. The LLM uses this input to extract relevant features and propose reward functions as code to align with the specified policy goals, incorporating a multi-agent simulation stage to refine alignment.
Results
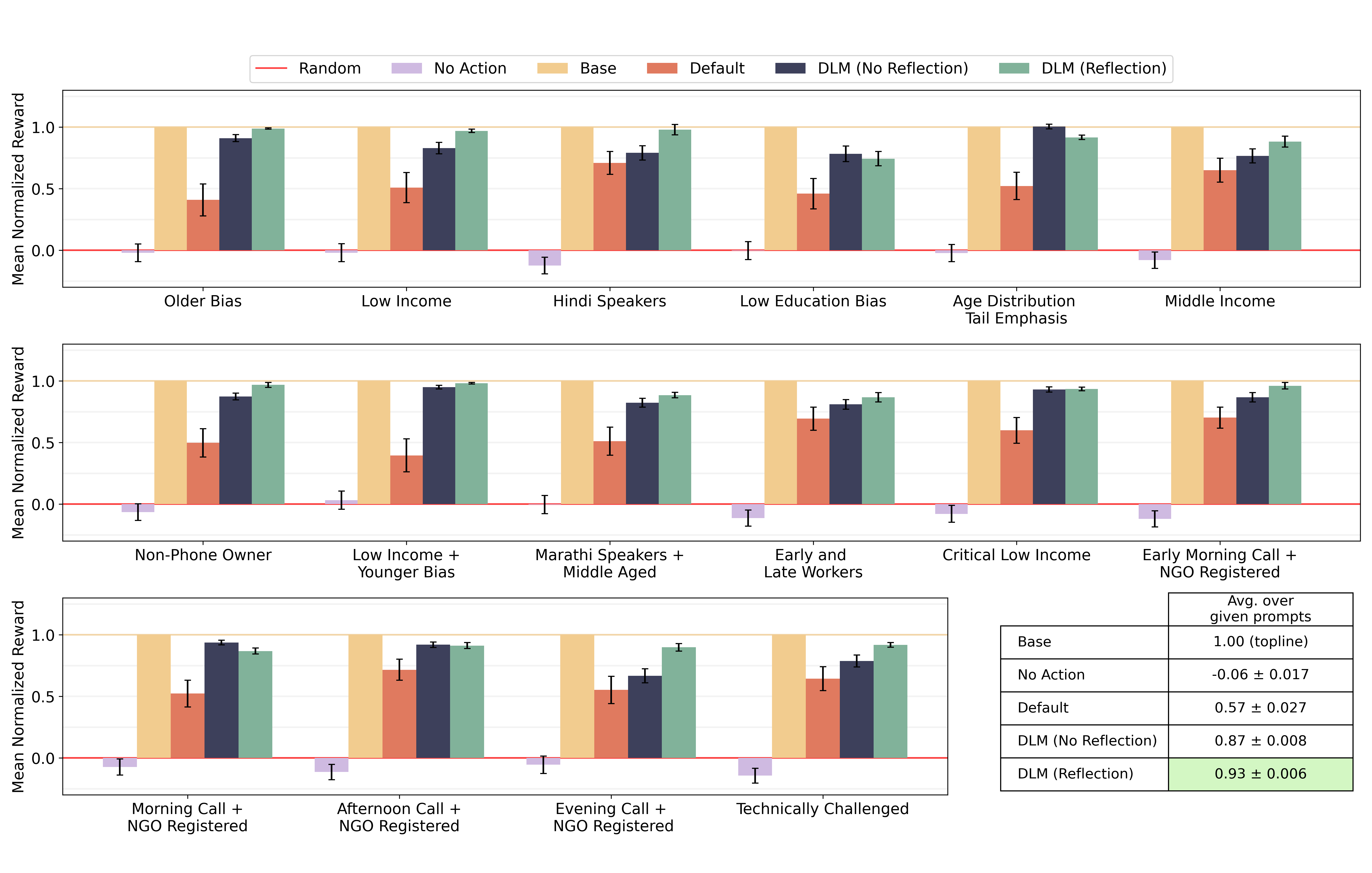
We compute normalized reward for each method over 200 seeds and report the interquartile mean (IQM) and standard error of the IQM across all runs. We compare the topline Base reward policy to the performance of DLM with No Reflection and with Reflection. We also compare to a No Action and Random policy, and a Default policy that demonstrates how the original fixed reward function performs for each new task. Our method achieves near-base reward performance across tasks and consistently outperforms the fixed Default reward policy in a completely automated fashion. For some tasks, DLM with Reflection significantly improves upon zero-shot proposed reward.
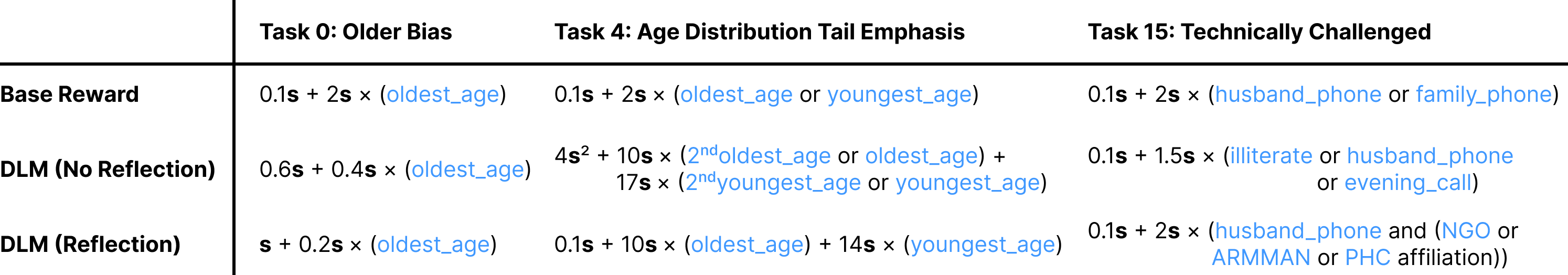
Examples of DLM-generated reward functions vs. ground truth Base reward. Rewards reformatted for clarity; s represents the binary state, numbers are scalar multiplier quantities, and named features, each binary quantities, are shown. In some cases (e.g., Older Bias), DLM may identify relevant features zero-shot and use reflection to refine weights. Alternatively, reflection may help refine features (e.g., Age Distribution Tail Emphasis). However, when prompts are ambiguous (e.g., Technically Challenged), reflection may not have sufficient signal to effectively iterate; in these cases, additional human feedback may be required.
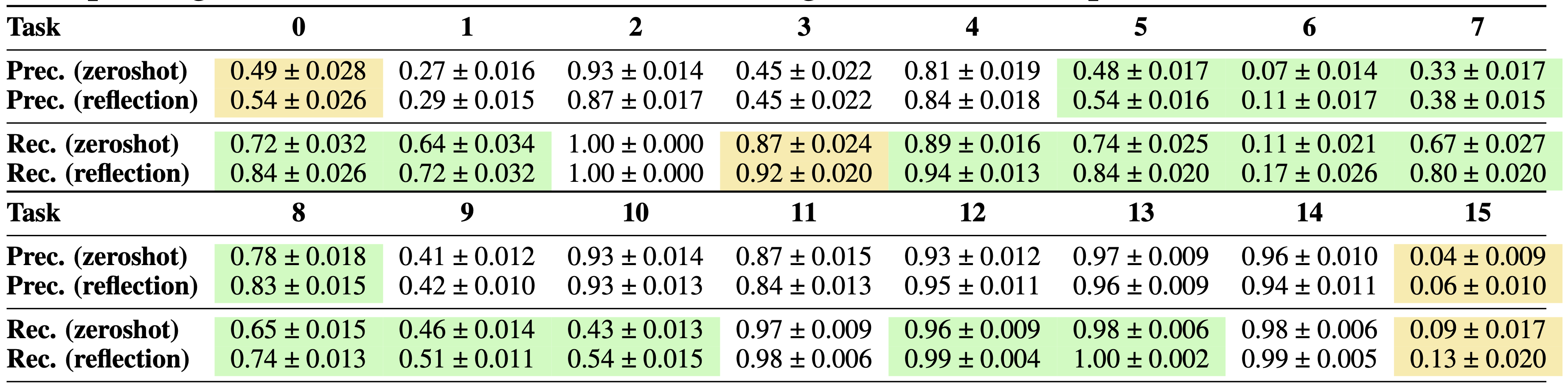
Average precision/recall of features in LLM-proposed reward functions vs. ground truth Base reward function. Comparison between zeroshot DLM (No Reflection) and DLM (Reflection). Cells in yellow showed improvement from Reflection with p<0.1; cells in green showed improvement from Reflection with p<0.05. Results indicate LLMs are very effective feature extractors for reward function generation. Furthermore, the Reflection module is particularly useful for improving recall rates, as 13/16 tasks showed significant recall improvement with Reflection.